
Introduction
Autonomous driving is entering a new era in 2025 with the emergence of Vision-Language-Action (VLA) models. These AI models represent a paradigm shift in how self-driving systems are designed, moving beyond traditional perception and control methods. In the autonomous driving industry, VLA models are rapidly gaining attention as a potential game-changer. They promise to integrate visual perception, language understanding, and decision-making (action) into a single framework. This integration is significant because it could allow self-driving cars to reason more like human drivers, adapt to complex scenarios, and even explain their decisions to us in real time. In this post, we’ll explore what VLA models are, why they matter, how industry leaders are adopting them, and whether they might represent the future (and perhaps the pinnacle) of autonomous driving technology.
What is VLA?
Vision-Language-Action (VLA) refers to AI models that combine visual inputs, language processing, and actionable outputs. In simpler terms, a VLA model can see (through cameras or sensors), think and reason in words, and then act (control the vehicle). This concept first appeared in the robotics field. In July 2023, Google DeepMind introduced Robotics Transformer 2 (RT-2) — the world’s first VLA model for controlling robots. RT-2 learned from both web data and real-world robotic data, allowing it to translate its broad knowledge into generalized instructions for robotic actions. This was a breakthrough demonstration that an AI could leverage internet-scale vision-language knowledge to perform physical tasks, showing a path to greater generalization in AI control systems.
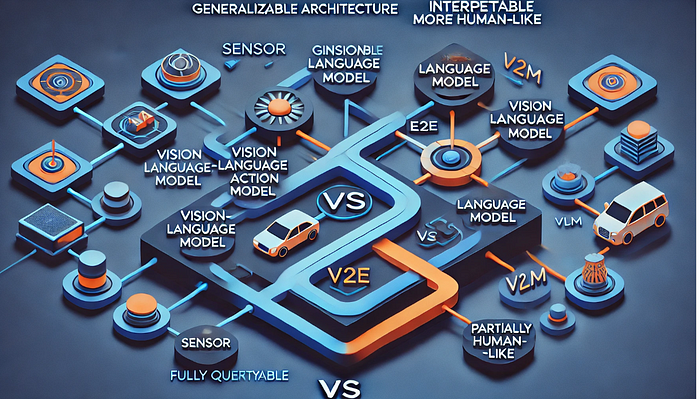
In autonomous driving, VLA models are seen as an evolution beyond both the traditional modular approach and the more recent end-to-end driving models. Traditional self-driving systems are modular — they have separate components for perception, prediction, planning, and control. Each module handles a specific task (detecting obstacles, planning a path, etc.), and they work in a pipeline. While this approach is proven, it can be complex and sometimes brittle, as errors can accumulate through the pipeline and the hand-crafted rules may not cover every scenario.
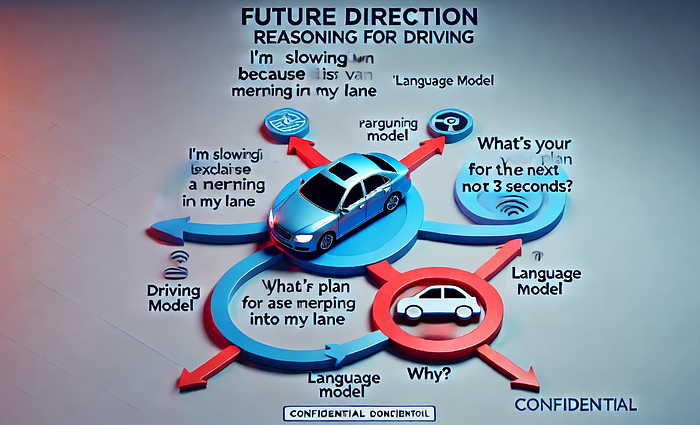
End-to-end models improved on this by training a single neural network to go straight from sensor inputs to driving controls. End-to-end learning (often using cameras to steering output) simplifies the stack but tends to operate as a black box with limited transparency or reasoning. This is where VLA models differ: a VLA model is typically end-to-end and multi-modal, meaning it takes raw sensor data and processes it through a neural network that includes a language component. The language component can serve as a reasoning layer — effectively a “thinking aloud” stage where the model internally represents what it sees in words or interprets commands. The outcome is a driving action. Because the model uses language in its decision process, it gains a form of explainability that pure end-to-end models lack. In fact, VLA systems are designed to be fully differentiable (trainable as one piece) while still allowing introspection into why a certain action was chosen
Advantages of VLA
Why are VLA models generating so much excitement? There are several key advantages to this approach:
- Improved Interpretability and Explainability: One of the biggest advantages is that VLA models can be much more transparent in their decision-making. Because they integrate a language reasoning process, they can potentially As a result, VLA models offer greater user trust — a driver or passenger can understand why the AI is making certain maneuvers. Researchers describe this as revealing the “chain of thought” of the AI, turning the black box into something more transparent. Enhanced interpretability not only builds trust but also helps engineers diagnose and improve the system.
- Enhanced Generalization through Vast Data: VLA models are often built on foundation models (like large vision-language models) trained on extremely large and diverse datasets. This means they carry a wealth of prior knowledge. In practice, a VLA driving model can generalize better to long-tail or novel scenarios that it hasn’t explicitly been trained on, because it can draw on concepts learned from web images and text. VLA models essentially embed a form of common sense and world knowledge into the driving policy. This broad knowledge could make autonomous vehicles more adept at handling rare or unexpected conditions (the so-called “edge cases” or long-tail scenarios) that would confuse a more narrowly trained system
- Lower Fine-Tuning and Data Requirements: Training traditional self-driving stacks or end-to-end models often requires collecting and labeling massive amounts of driving data for every new feature or environment. VLA models, by leveraging a pre-trained foundation (for example, a language model that already learned semantics from billions of sentences, or a vision model trained on millions of images), can reduce the amount of task-specific data needed. In other words, much of the AI’s knowledge is generic and already learned, so developers might only need to fine-tune the model on relatively smaller driving datasets to specialize it. This can drastically cut down on the data collection and fine-tuning costs. Instead of training a model from scratch for each car model or scenario, companies can adapt a general VLA model. Furthermore, because VLA is one integrated model, any improvements (like new data or better training techniques) benefit the whole system, rather than updating multiple separate modules. This efficiency is highly attractive from a development and maintenance perspective.
- Unified Goal Optimization: Another advantage is that a VLA model optimizes the entire driving task end-to-end, which can lead to better overall performance. Traditional systems sometimes struggle to balance the objectives of different modules (for instance, vision might maximize detection accuracy at the expense of speed, whereas planning cares about comfort, etc.). In a single VLA network, the optimization is holistic — the model learns to do what leads to the best driving outcome (as defined by reward or loss functions) considering perception and action together. Early results from companies using VLA hints at improved driving smoothness and decision quality because of this unified learning. For example, industry experts note that VLA can directly generate motion plans from perception in a way that’s closer to the ideal “image in, control out” driving dream
Is VLA the Future of Autonomous Driving?
Given the momentum behind Vision-Language-Action models, a bold question arises: Is VLA the final stage for autonomous driving AI? In other words, are we heading toward a future where every self-driving car is powered by a VLA brain, and is that the pinnacle of the technology? There are strong arguments on both sides.
On one hand, VLA models indeed look like the future of autonomous driving, or at least a very critical part of it. Many industry experts view VLA as the key to unlocking higher levels of driving autonomy and capability. A recent Goldman Sachs report even projected that by 2030, end-to-end autonomous driving solutions dominated by VLA models could occupy 60% of the Level 4 autonomous driving market. That implies VLA could become the de facto approach for nearly two-thirds of all highly-automated vehicles in the next decade — a huge vote of confidence in this direction. If this plays out, companies that master VLA could dominate the autonomous driving landscape, and traditional modular or rule-based systems may become obsolete for advanced autonomy. The rationale is that as VLA models continue to learn and scale, their performance will keep improving, eventually surpassing human driving abilities in safety and efficiency. Additionally, VLA aligns with the broader AI trend of using foundation models and general AI techniques, suggesting that autonomous driving is converging with the general AI frontier. We’re not just building better driving algorithms; we’re teaching cars to understand and reason about the world like human-like intelligent agents. That vision is incredibly exciting and forward-looking. It hints that a car’s AI might eventually be as general as some of the AI assistants we see in other domains — capable of conversing with passengers, navigating novel situations, and learning new skills on the fly.
In summary, VLA models bring together the strengths of deep learning and large-scale training (learn from huge amounts of data, find patterns, generalize) with the added semantic understanding and explainability of language. The outcome is an autonomous driving AI that is potentially smarter, safer, and easier to trust than previous generations.